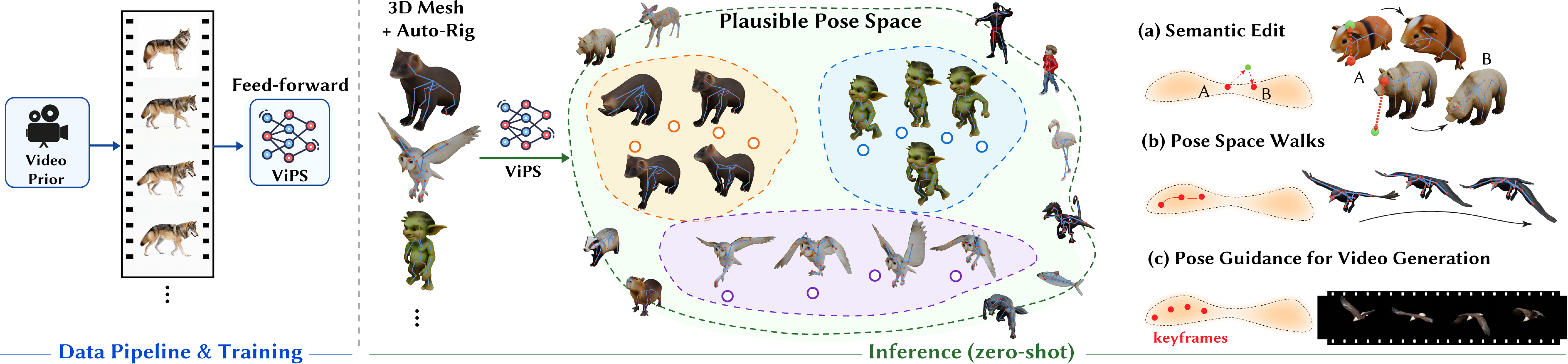
Overview
We first build a dataset of rigged meshes and plausible skeleton poses by combining video priors, per-frame 3D reconstruction, skeleton extraction, and pose optimization. We then train a diffusion model conditioned on the mesh and skeleton to model the distribution of plausible poses. At inference, we sample from the model, invert poses with DDIM inversion, and apply sparse constraints through guidance.
Rigged mesh poses from a video prior. We generate single-object videos with image-to-video priors, reconstruct per-frame meshes and align them in a common world space, then extract a skeleton from the first frame and optimize node positions to match each frame using Chamfer distance and edge-length regularization.

Learning a pose space. We train a diffusion model to denoise poses conditioned on the mesh, skeleton edges, rest pose, and semantic node features. Sampling uses a standard denoising schedule.
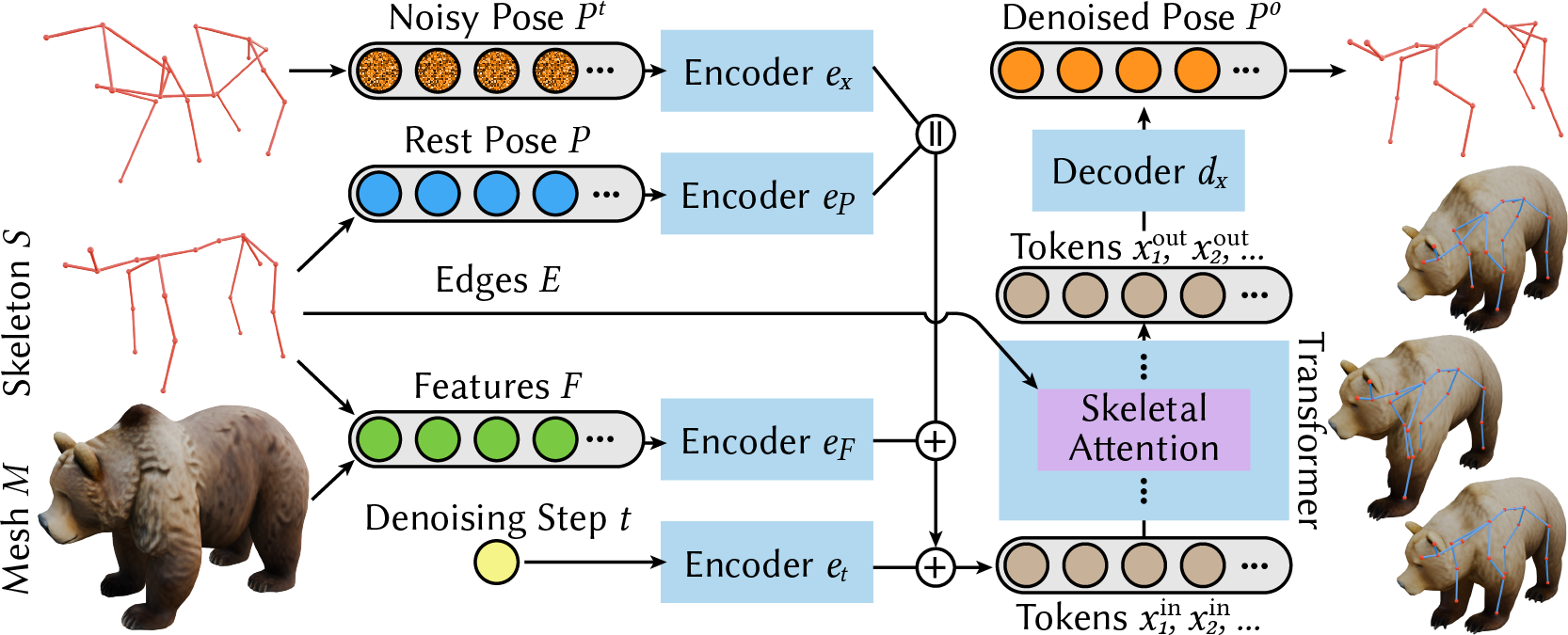
Constrained sampling. We reproduce a pose via DDIM inversion into a noise sample, and apply sparse constraints by nudging the denoising trajectory using an energy term.
Contributions
- We formulate pose space discovery as learning a universal, mesh-conditioned generative distribution over rig parameters. Unlike 4D reconstruction methods that recover specific motion instances, ViPS learns a continuous manifold of valid configurations, enabling semantic pose edits and pose-space walks.
- We distill video-to-pose supervision through a video diffusion model, transferring motion priors into rig space without curated 3D or 4D motion/pose data and helping cover the long tail of shape variation.
- We introduce a high-quality 4D motion dataset with correspondence, containing 127k poses across 100+ species and 200+ unique individuals, built from generative video priors with VLM guidance and 4D reconstruction.
All examples below are from assets unseen during training, using only the rest mesh and its auto-rig as input.
Qualitative Comparisons
Additional Zero-shot Results
Hover to show view 2.
Pose Walks
To visualize the continuity of the learned pose space, we generate pose-space traversals by interpolating in latent noise space and decoding each intermediate step. We first obtain the noisy latent xT for the start and end poses using deterministic DDIM inversion (η = 0), then interpolate between them using variance-preserving interpolation, and decode each step with DDIM. This produces smooth, semantically meaningful transitions that remain on the learned manifold, in contrast to direct interpolation in joint space.





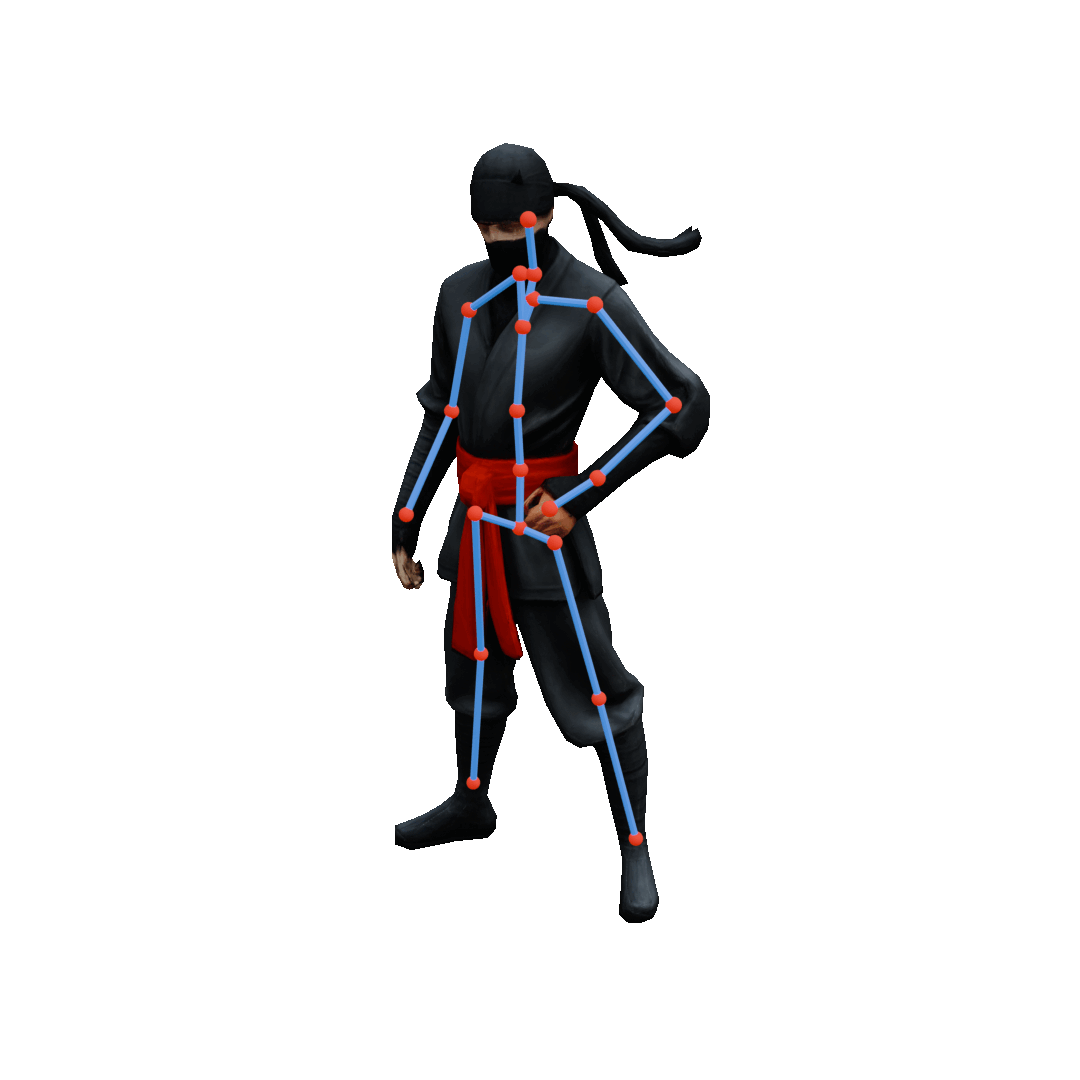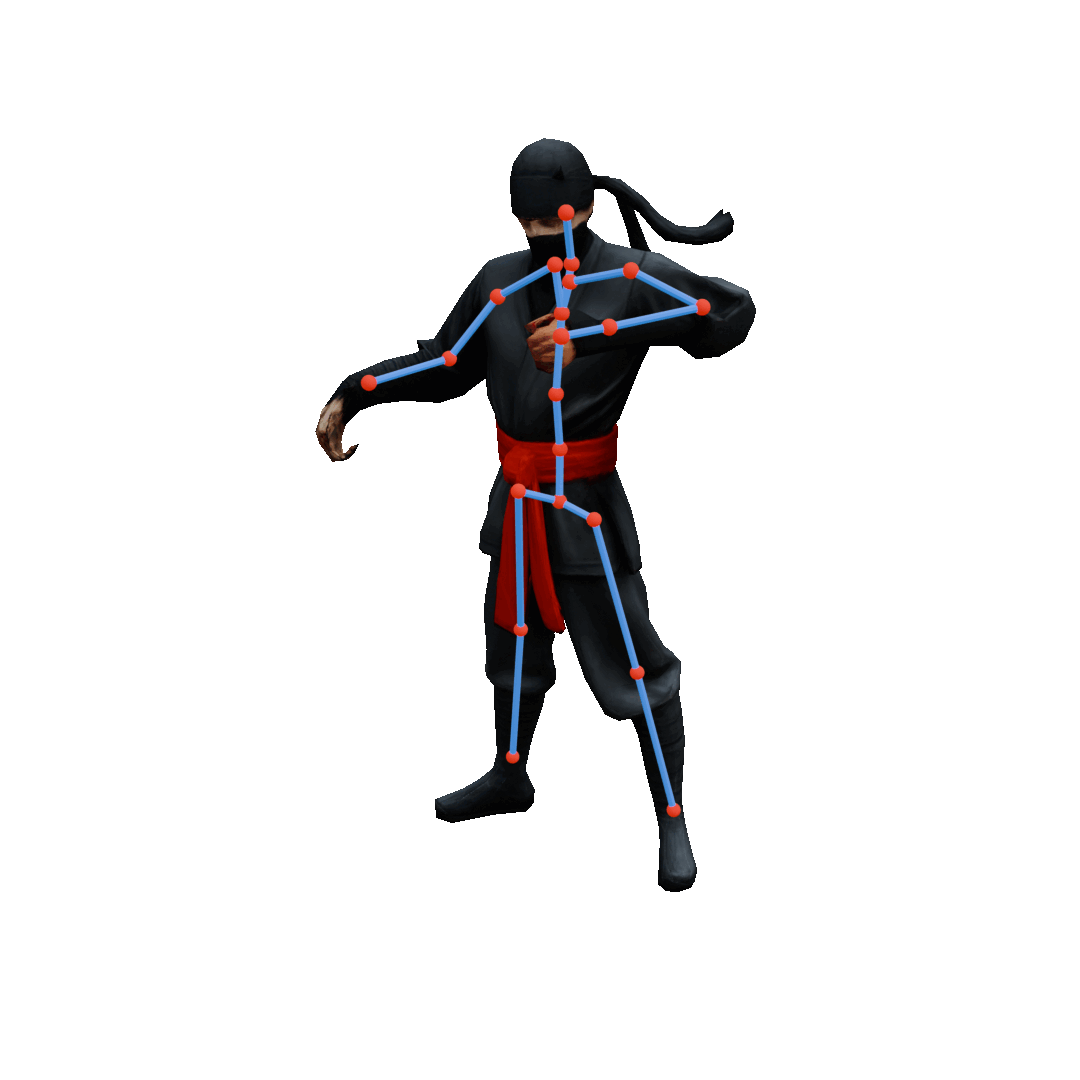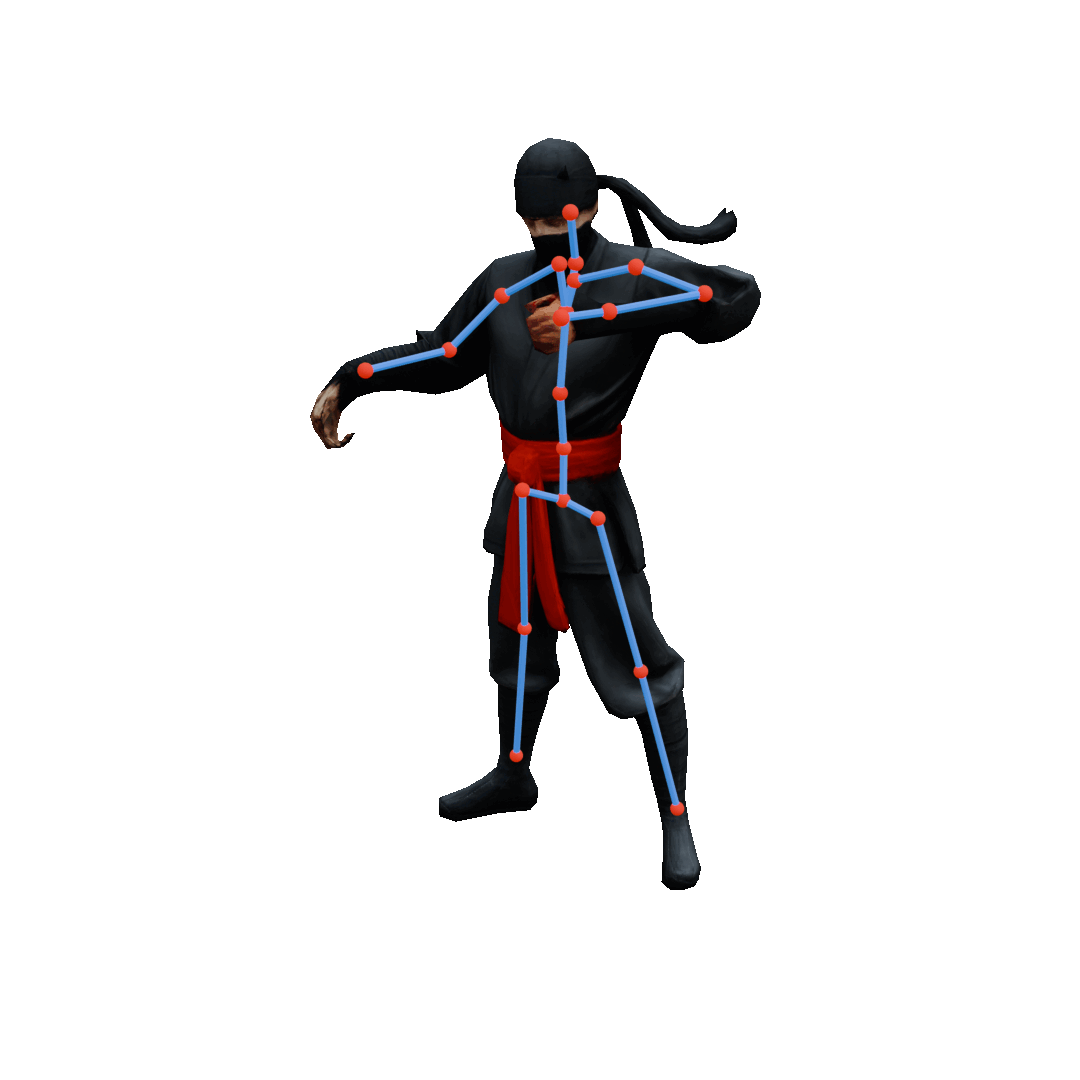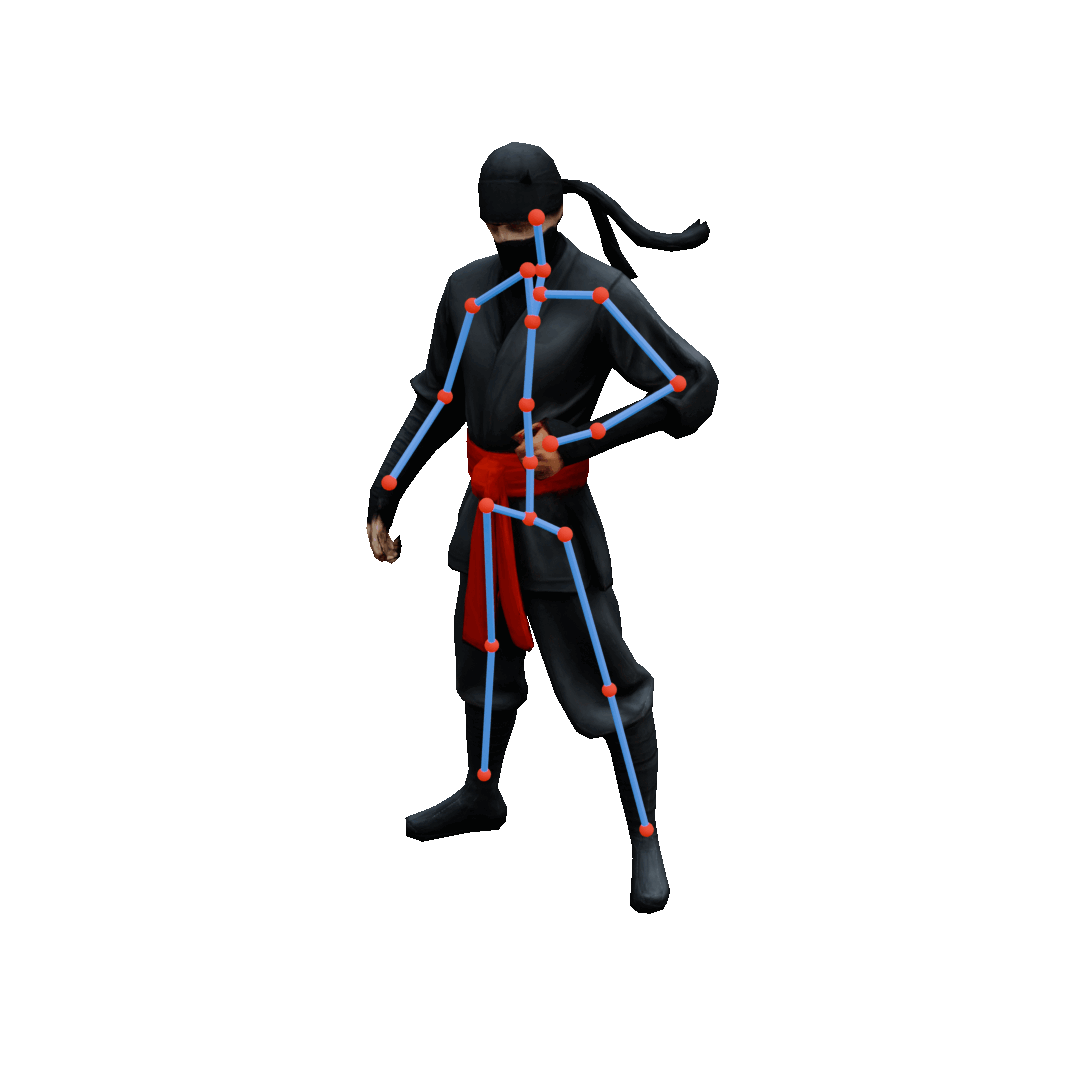









Semantic Pose Editing
ViPS enables precise inverse kinematics by projecting user-driven joint handles (orange → green) into the discovered plausible pose space. It generates poses that remain faithful to the learned prior while approximately satisfying sparse user constraints through guided sampling, where an energy function measures constraint violation and nudges each denoising step toward lower energy.

Controllable Video Generation
Our pose space provides a simple interface for generating keyframes that can steer a video diffusion model. We select keyframes along a pose-space traversal (or between edits), render the corresponding mesh+skeleton proxy, and supply these as conditioning frames. This enables controllable, semantically aligned video generation: the video model is free to synthesize appearance and texture, while the pose sequence provides precise 3D control.
Data Pipeline
We introduce a high-quality 4D motion dataset with correspondence, containing 127k poses spanning 100+ species and 200+ unique individuals built from generative video priors with VLM guidance and 4D reconstruction. The dataset will be released upon acceptance.
Data Pipeline Comparison
We compare our generated data with Puppeteer independently of the feed-forward model. Both pipelines reconstruct poses from video frames; here, our pipeline fits poses to videos generated from scratch, while Puppeteer requires videos initialized from a render of the rest-pose mesh Mα. Puppeteer can miss limb configurations due to tracking errors under self-occlusion or large motion, whereas our 4D reconstruction avoids explicit inter-frame tracking and better follows the video frames.
Different Video Model Priors
Our data pipeline can be integrated with different video models as motion priors.
Using the same input image and
the same text prompt describing a robot runningA metallic humanoid robot with articulated joints and a sleek design stands in a static, full-body shot against a plain white background. The robot begins to run, showcasing its smooth motion and mechanical precision. Each step is fluid and realistic, maintaining natural weight and timing typical of a metallic structure. The environment remains simple and light-stable, ensuring a clear and stable view of the robot's running action from a fixed tripod position. The scene highlights the robot's dynamic movement without introducing any additional elements or transitions. The video is rendered in photorealistic, 4k, high-fidelity quality.,
we show pose optimization results obtained by swapping our current video prior,
Wan2.2-TurboDiffusion, with Kling, Runway, and SeedDance.
and
the same text prompt describing a robot runningA metallic humanoid robot with articulated joints and a sleek design stands in a static, full-body shot against a plain white background. The robot begins to run, showcasing its smooth motion and mechanical precision. Each step is fluid and realistic, maintaining natural weight and timing typical of a metallic structure. The environment remains simple and light-stable, ensuring a clear and stable view of the robot's running action from a fixed tripod position. The scene highlights the robot's dynamic movement without introducing any additional elements or transitions. The video is rendered in photorealistic, 4k, high-fidelity quality.,
we show pose optimization results obtained by swapping our current video prior,
Wan2.2-TurboDiffusion, with Kling, Runway, and SeedDance.
Runway
SeedDance
Wan2.2-TurboDiffusion
Our Data vs. Artist Data
We compare artist-authored motion clips against samples from our generated data. The quality of artist-authored motion varies considerably across data sources. Free, open-source datasets such as Objaverse-XL often contain animations whose quality varies substantially depending on the asset origin and animator effort. and they may offer limited motion diversity for a specific object. In contrast, commercial datasets such as Truebones Zoo can provide higher-quality animations, but they are typically smaller in scale and more expensive to acquire.
Astronaut
Pteranodon
Limitations
Our method is still constrained by the input auto-rig, so issues such as poor bone placement, inaccurate skinning weights, or suboptimal topology can directly limit the learned pose space. It also inherits biases from the video prior and 4D extraction, which may struggle with rare motions, unusual species, or non-biological objects. More broadly, the current framework models plausible static articulations rather than full motion dynamics, and it does not yet capture more complex deformation behaviors such as soft materials, topology changes, or secondary physical effects.
BibTeX
@article{chen2025vips,
title = {ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes},
author = {Chen, Honglin and Pandey, Karran and Wu, Rundi and Gadelha, Matheus and Hold-Geoffroy, Yannick and Tewari, Ayush and Mitra, Niloy J. and Zheng, Changxi and Guerrero, Paul},
journal = {arXiv preprint arXiv:2026.XXXXX},
year = {2026}
}